Support Vector Machines for Classification Article Swipe
 YOU?
·
· 2015
· Open Access
·
· DOI: https://doi.org/10.1007/978-1-4302-5990-9_3
· OA: W2230508580
YOU?
·
· 2015
· Open Access
·
· DOI: https://doi.org/10.1007/978-1-4302-5990-9_3
· OA: W2230508580
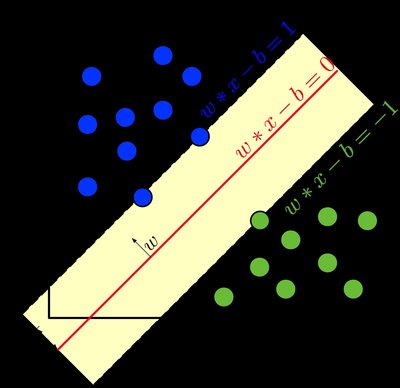
This chapter covers details of the support vector machine (SVM) technique, a sparse kernel decision machine that avoids computing posterior probabilities when building its learning model. SVM offers a principled approach to problems because of its mathematical foundation in statistical learning theory. SVM constructs its solution in terms of a subset of the training input. SVM has been extensively used for classification, regression, novelty detection tasks, and feature reduction. This chapter focuses on SVM for supervised classification tasks only, providing SVM formulations for when the input space is linearly separable or linearly nonseparable and when the data are unbalanced, along with examples. The chapter also presents recent improvements to and extensions of the original SVM formulation. A case study concludes the chapter.