No more fine-tuning? an experimental evaluation of prompt tuning in code intelligence Article Swipe
 YOU?
·
· 2022
· Open Access
·
· DOI: https://doi.org/10.1145/3540250.3549113
· OA: W4288055447
YOU?
·
· 2022
· Open Access
·
· DOI: https://doi.org/10.1145/3540250.3549113
· OA: W4288055447
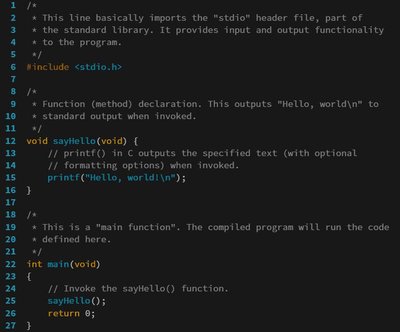
Pre-trained models have been shown effective in many code intelligence tasks.\nThese models are pre-trained on large-scale unlabeled corpus and then\nfine-tuned in downstream tasks. However, as the inputs to pre-training and\ndownstream tasks are in different forms, it is hard to fully explore the\nknowledge of pre-trained models. Besides, the performance of fine-tuning\nstrongly relies on the amount of downstream data, while in practice, the\nscenarios with scarce data are common. Recent studies in the natural language\nprocessing (NLP) field show that prompt tuning, a new paradigm for tuning,\nalleviates the above issues and achieves promising results in various NLP\ntasks. In prompt tuning, the prompts inserted during tuning provide\ntask-specific knowledge, which is especially beneficial for tasks with\nrelatively scarce data. In this paper, we empirically evaluate the usage and\neffect of prompt tuning in code intelligence tasks. We conduct prompt tuning on\npopular pre-trained models CodeBERT and CodeT5 and experiment with three code\nintelligence tasks including defect prediction, code summarization, and code\ntranslation. Our experimental results show that prompt tuning consistently\noutperforms fine-tuning in all three tasks. In addition, prompt tuning shows\ngreat potential in low-resource scenarios, e.g., improving the BLEU scores of\nfine-tuning by more than 26\\% on average for code summarization. Our results\nsuggest that instead of fine-tuning, we could adapt prompt tuning for code\nintelligence tasks to achieve better performance, especially when lacking\ntask-specific data.\n