Identifier Splitters Article Swipe
 YOU?
·
· 2015
· Open Access
·
· DOI: https://doi.org/10.5281/zenodo.439585
· OA: W4393665372
YOU?
·
· 2015
· Open Access
·
· DOI: https://doi.org/10.5281/zenodo.439585
· OA: W4393665372
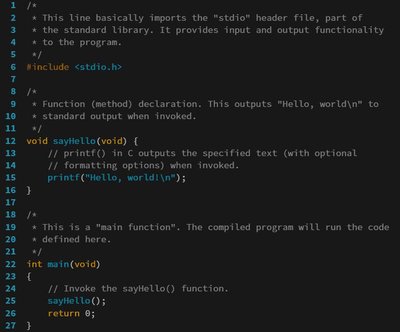
The oracle, found in the file loyola-udelaware-identifier-splitting-oracle (ludiso) consists of 2663 identifiers. These identifiers were split by volunteers using a web interface. In all 8522 splitting judgements were collected for 2731 identifiers. The data set was curated based on the sum of confidence associated with a particular split. In order to provide a single correct split in the oracle, the split receiving the highest confidence sum was used as the correct split. Of the 2731 identifers, 68 do not appear in the oracle because of ties. (These identifiers can be found in the raw data.) Details on the construction of the oracle can be found in "An empirical study of identifier splitting technique". <strong>Attribute Information</strong> Each line of the oracle represents one of the 2663 remaining oracle identifiers and includes the following. the identifier's unique identification number,<br> the original identifier as extracted from the source,<br> the dominant language of the program that the id was extracted from,<br> the program from which it was extracted,<br> the identifier as shown to subjects where a '-' denotes a hard split,<br> the number of splittings (always 1 in the oracle, but not in the raw data),<br> the identifier as split by users,<br> the number of confidences (1 - 5) and then each confidence.<br>